定常性の検定は、将来の予測や統計的分析を行う上で重要です。
定常性とは、時系列データの統計的性質が時間に依存しないことを指し、平均や分散、自己相関が一定であることを意味します。
また、自己相関分析とは、時系列データ内のデータ点とそのタイムラグとの間の相関を計算する統計的手法です。
自己相関分析の目的は、パターンの特定や適切な時系列モデルの選択などです。
この記事では、定常性のADF検定を使った定常性の検定方法や、コレログラムを使って自己相関、偏自己相関を確認する方法について書いています。
プログラミング、機械学習など、無料体験はこちら↓↓↓
![]()
定常性の検定
定常性とは
定常性(Stationarity)の検定は、時系列データが定常過程(Stationary process)であるかどうかを確認するための統計的な手法です。
定常性(Stationarity)は、時系列データの統計的性質が時間に依存しないことを指し、主に以下の三つの特性を持つ時系列データが定常性を持っていると言えます:
1. 平均の一定性(Constant Mean): 時系列データの平均値が時間によらず一定であること、つまり、データの長期的な平均が変化しないということです。
2. 分散の一定性(Constant Variance): 時系列データの分散(ばらつき)が時間によらず一定であること。
簡単に言えば、データのばらつきが時間とともに変化しないということです。
3. 自己共分散や自己相関の一定性(Constant Autocovariance/Autocorrelation): 時系列データの自己共分散や自己相関が時間の経過に関係なく一定であることを意味します。
つまり、データの相互関係が時間によらず一定であるということです。
時系列分析において定常性の検定が必要な理由
定常性を持つ時系列データは、その統計的性質が時間に依存しないため、将来の予測や統計的分析が安定して行えます。
さらに、多くの時系列解析手法や予測モデルは、データが定常性を持つことを前提としています。
しかし、非定常性(Non-stationarity)を持つ時系列データは、統計的性質が時間によって変化するため、予測や分析が困難となる場合があるのです。
そのため、非定常性を持つデータに対しては、分析前の前処理など定常性を持つデータよりも複雑ン位なります。
定常性の検定手法
定常性の検定では、通常、単位根検定(Unit Root Test)などの統計的な検定手法が用いられます。
単位根検定は、時系列データが単位根を持つかどうかを検定する手法で、代表的な単位根検定としては、ADF検定(Augmented Dickey-Fuller test)やKPSS検定(Kwiatkowski-Phillips-Schmidt-Shin test)などがあります。
単位根とは
単位根(Unit Root)を持つとは、時系列データが非定常性(Non-stationarity)を示す性質を持っていることを指します。
非定常性を持つとは、データの統計的性質が時間に依存している、つまり時間の経過とともに平均値が変化したり、トレンドを持ったりする特徴があります。
単位根を持つデータは非定常性を示すため、多くの時系列解析手法や予測モデルは適用することができません。
そのため、データの非定常性を解消するための一般的な手法としては、差分化(Difference)や対数変換(Logarithmic Transformation)などのデータ変換が使われます。
ADF検定(Augmented Dickey-Fuller test)
ADF検定(Augmented Dickey-Fuller test)は、時系列データが単位根を持つかどうかを検定するための統計的手法であり、データにトレンド(trend)や季節性(seasonality)が存在する場合にも適用することができます。
ADF検定では、以下のような帰無仮説(null hypothesis)と対立仮説(alternative hypothesis)を検定します。
帰無仮説(H0): データに単位根(非定常性)が存在する
対立仮説(H1): データに単位根(非定常性)が存在しない
ADF検定の統計量は、帰無仮説のもとでの係数のt値(t-statistic)です。このt値を用いて、帰無仮説を棄却するかどうかを判断します。
今回の時系列分析では、ADF検定を使って単位根の有無、つまりデータの定常性の有無を検定します。
現系列に対するADF 検定
まず、現系列に対するADF検定を行ってみます。
# # 原系列に対するADF検定 # # ADF検定 dftest = adfuller(df_corn_m1508.終値) # 出力 print('ADF Statistic:', dftest[0]) print('p-value:', dftest[1]) print('Critical values:') for i, j in dftest[4].items(): print('\t', i, j)
ADF Statistic: -1.5092557509243585
p-value: 0.5289277835443865
Critical values:
1% -3.5003788874873405
5% -2.8921519665075235
10% -2.5830997960069446
ここで見る必要があるのが、いくつかの数値が出力されましたが、見る必要があるのは p-value になります。
原系列におけるADF検定の場合 p-value は0.529、つまりp値>0.05なので、帰無仮説は棄却されず、データに単位根が存在する、つまり非定常であると言えます。
現系列の差分系列(1か月)を生成
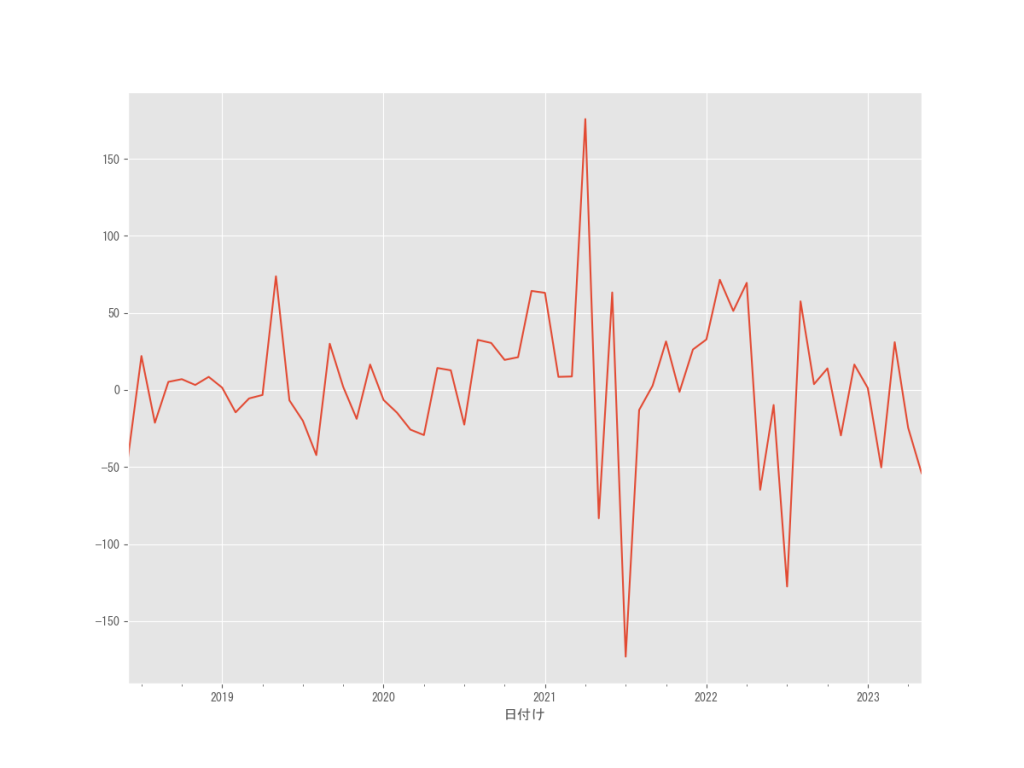
では、現系列から差分1ヶ月を生成したデータでADF検定を行ってみましょう。
# # 原系列の差分系列(1ヶ月)を生成 # # 差分系列の生成 df_m1 = df_corn_m1508.終値.diff(1).dropna() # グラフで確認 df_m1.plot()
ADF検定を行ってみます。
# # 原系列の差分系列(1ヶ月)に対するADF検定 # # ADF検定 dftest = adfuller(df_m1) # 出力 print('ADF Statistic:', dftest[0]) print('p-value:', dftest[1]) print('Critical values:') for i, j in dftest[4].items(): print('\t', i, j)
ADF Statistic: -5.713949173521226
p-value: 7.192650902854267e-07
Critical values:
1% -3.5003788874873405
5% -2.8921519665075235
10% -2.5830997960069446
原系列の差分系列1ヶ月に対すADF検定結果を見てみると、p-value が 0.00046と p値<0.05。
有意差があるので帰無仮説は棄却されるため、データは単位根を持つ非定常データであるとは言えません。
現系列の差分系列(12か月)の差分系列
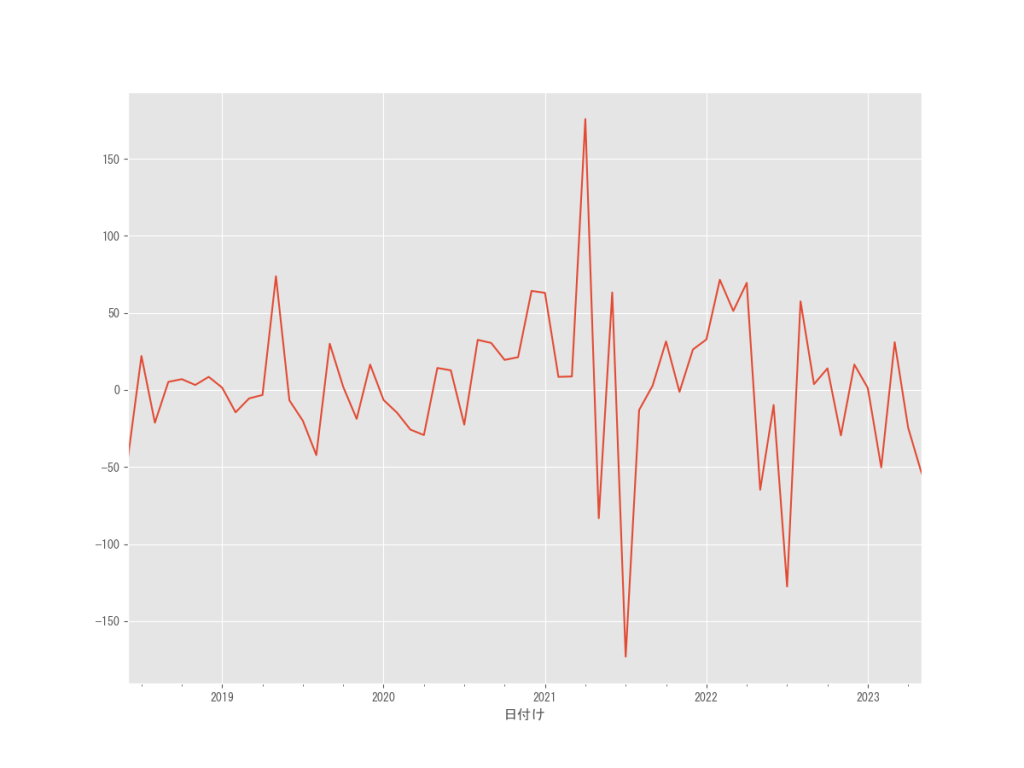
さらに原系列の差分系列1ヶ月の差分系列12か月のADF検定を行ってみます。
# # 原系列の差分系列(1ヶ月)の差分系列(12ヶ月)の生成 # # 差分系列の生成 df_m1_M12 = df_m1.diff(12).dropna() # グラフで確認 df_m1_M12.plot() plt.savefig('シカゴコーン先物月別推移2018-5-1-2023-8-1差分1か月の12か月') #plt.show()
ADF Statistic: -5.335902669293453
p-value: 4.6118825052810136e-06
Critical values:
1% -3.5097356063504983
5% -2.8961947486260944
10% -2.5852576124567475
結果を見てみると、このデータでもp値<0.05と帰無仮説は棄却されるため、単位根があり非定常とは言えません。
自己相関と偏自己相関 (ACF & PACF)
自己相関分析とは
自己相関分析(Autocorrelation analysis)は、時系列データの中に存在する自己相関(自己相関係数)を調べる統計的な手法です。
自己相関分析では、時系列データの各データ点と一定のタイムラグ(ラグ)を持つデータ点との間の相関を計算します。具体的には、データ点とそのラグに対応するデータ点の間の相関係数を求めます。
自己相関分析によって得られる自己相関係数は、-1から1までの値を取り、自己相関係数が1に近い場合、過去のデータと現在のデータは強い正の相関ががある可能性があり、逆に、自己相関係数が-1に近い場合は強い負の相関があります。
自己相関分析の目的
1. 自己相関分析によって、時系列データ内の周期性やトレンドなどパターンの特定。
2. 自己相関のパターンを分析することで、適切な時系列モデルを選択する手がかりとする。
3. 自己相関係数の絶対値が高い場合、そのラグは予測に有用な情報を持っている可能性あり。
4. モデルの診断:構築した時系列モデルの診断に自己相関分析を利用すること。
偏自己相関分析とは
偏自己相関分析(Partial Autocorrelation Analysis)は、時系列データにおける各データ点とラグを持つ他のデータ点との間の相関を調べる統計的な手法です。
自己相関分析と同様に、時系列データの特性や相関関係を理解するために使用されますが、偏自己相関分析では他の変数の影響を制御して、直接の関連性を評価します。
例えば、ラグkのデータ点とラグlのデータ点との間の偏自己相関は、データ点間の相関を計算する際にラグkとラグl以外のデータ点を制御変数として考慮した結果となります。
偏自己相関の絶対値が高い場合、そのラグは他のラグを介さずに直接的な影響を持っている可能性があり、このような情報を利用して、時系列データのパターンやモデルの特性を解釈したり、予測モデルを構築する際に有用な情報を得ることができます。
偏自己相関分析は、自己相関分析と組み合わせて使用することが一般的であり、自己相関分析では全体的な相関関係を評価し、偏自己相関分析では直接の相関を評価することで、時系列データの相関関係をより詳細に分析することができます。
原系列の自己相関と偏自己相関のコレログラム
さっそく原系列の自己相関と偏自己相関をコレログラムで見てみましょう。
acf = plot_acf(df_corn_m1508.終値, lags=12) #自己相関
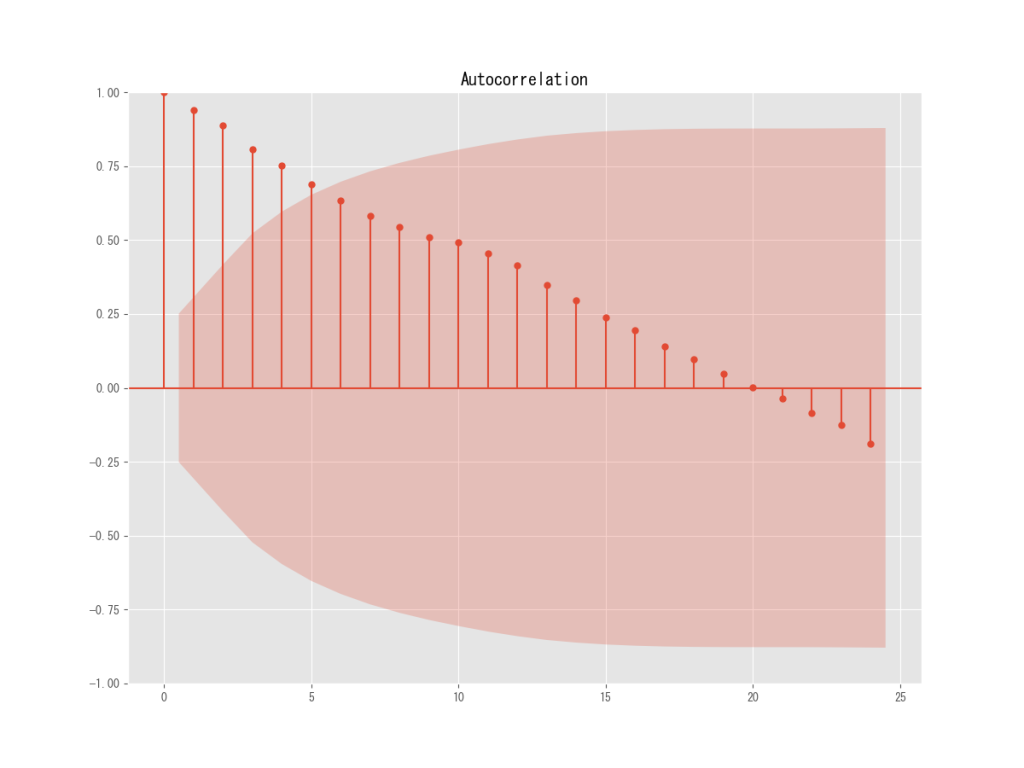
自己相関のコレログラムですが、周期があるといえば20ヶ月目で相関関係がポジティブからネガティブに変化しているということぐらいでしょうか。
それ以外は特に目立った季節性は見ることができませんね。
次に偏自己相関を見てみましょう。
pacf = plot_pacf(df_corn_m1508.終値, lags=12) #偏自己相関
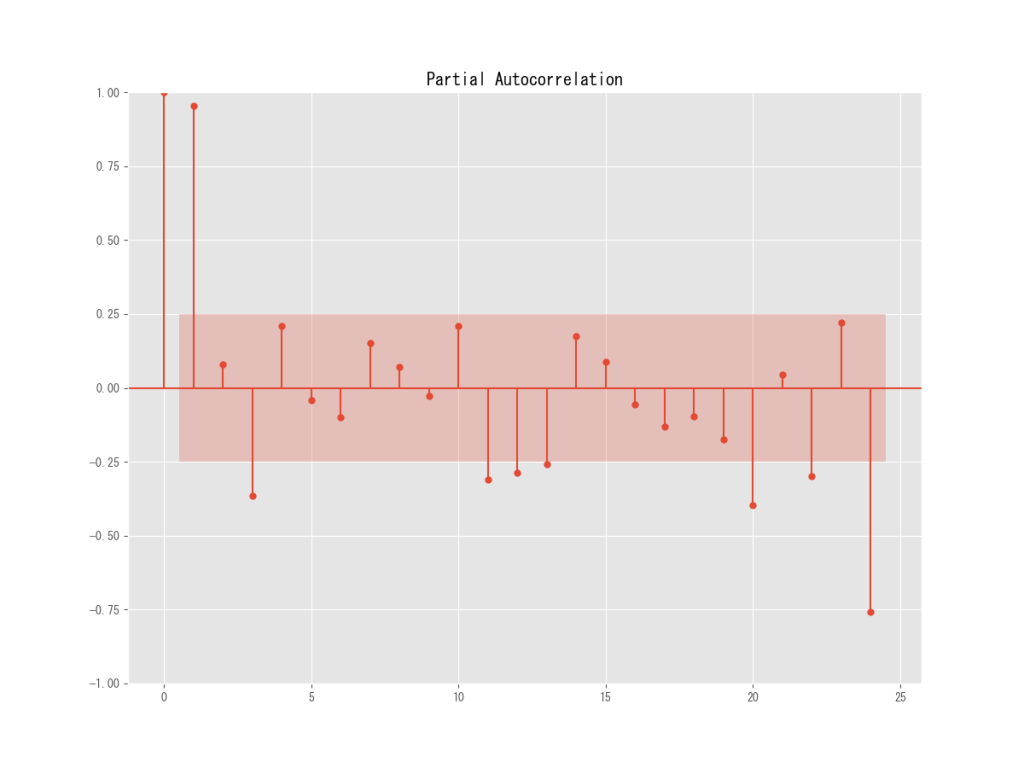
こちらもパターンがあるようでないような何とも言えないグラフになっています。
ではもう少しデータを分かりやすくするために、1ヶ月の差分系列の自己相関と偏自己相関を見てみましょう。
現系列の差分系列(1か月)
さらに現系列の1か月差分系列を見てみましょう。
acf = plot_acf(df_m1, lags=12) #自己相関
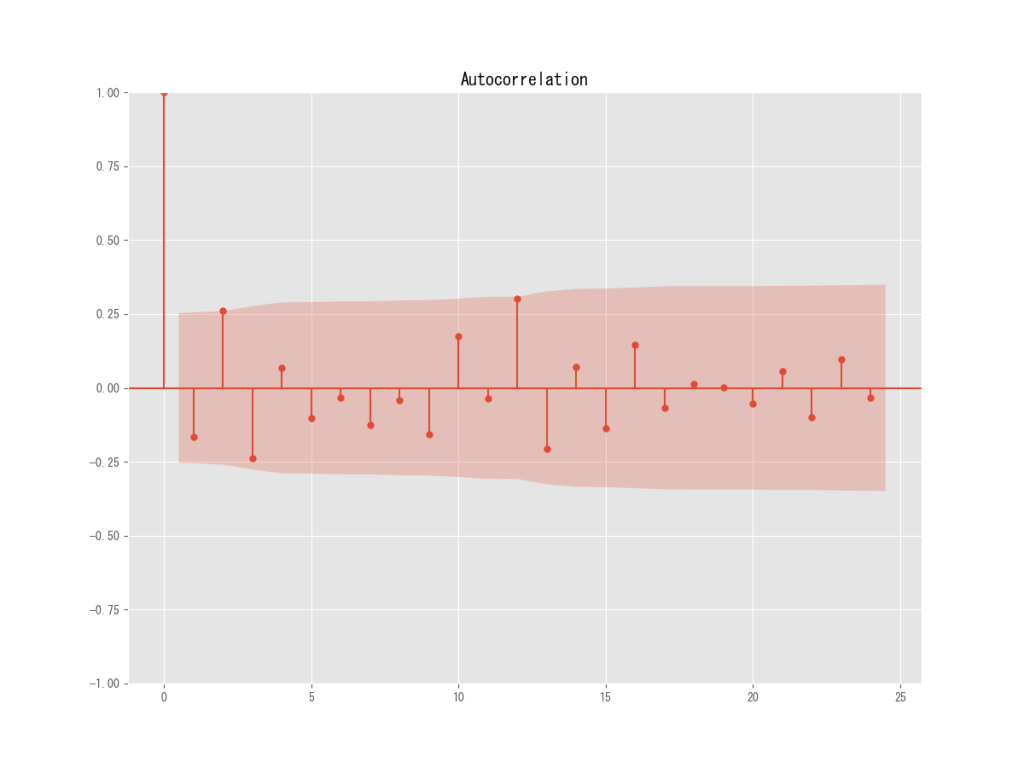
差分系列の自己相関を見てみると、10か月ごとに季節性があるように見えますね。
これを偏自己相関で見るとどうなるでしょうか。
pacf = plot_pacf(df_m1, lags=12) #偏自己相関
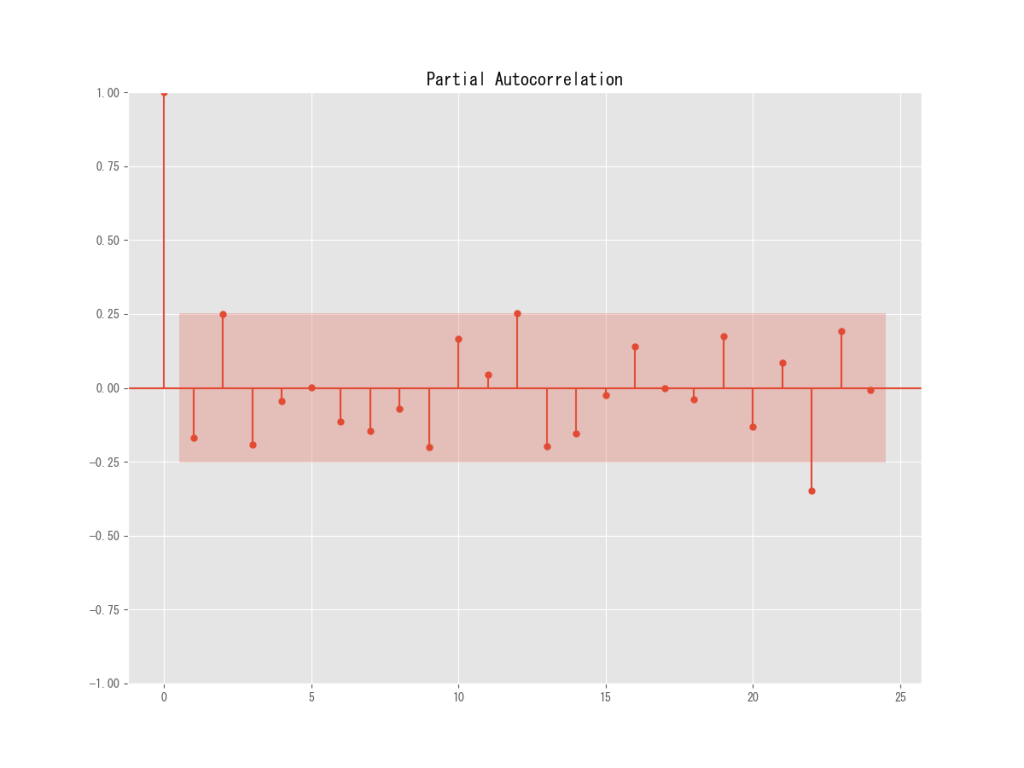 やはり10か月ごとの季節性が顕著に見えますね。
やはり10か月ごとの季節性が顕著に見えますね。
しかし20か月目にはネガティブに変化していていますので、基本的に原系列と同じような結果になっていると言えます。
まとめ
定常性の検定は、将来の予測や統計的分析において重要な要素であり、時系列データの統計的性質が時間に依存しない、つまり平均や分散、自己相関が一定であることを指します。
自己相関分析は、時系列データ内のデータ点とそのタイムラグとの相関を計算する手法であり、パターンの特定や適切な時系列モデルの選択に役立ちます。
この記事では、定常性の有無を判断するための統計検定であるADF検定、自己相関や偏自己相関のパターンを可視化するグラフ、コレログラムを利用する方法について説明しています。
これらの手法を適用することで、時系列データの性質を評価し、適切な分析手法やモデル選択に役立てることができます。
プログラミング、機械学習など、無料体験はこちら↓↓↓
![]()
関連記事↓↓↓


コメント