Pythonを使った時系列データの特徴抽出に限らず、データを分析する際にはデータの前処理が必要です。
この記事では、時系列データの性質を理解し、トレンドや季節変動、不規則性を識別する方法、平滑化などの処理方法を解説します。
プログラミング、機械学習など、無料体験はこちら↓↓↓
![]()
Pythonで実践する時系列データの特徴抽出に必要な処理
特徴抽出に必要なライブラリとデータのインポート
ここでは、pythonを用いたデータ分析のための特徴抽出に必要なPandas、Numpy、matplotlibなどのライブラリの実装について説明します。
ライブラリのインポート
特徴抽出には以下のPythonライブラリが必要です。
Pandas
PandasはPythonで使用されるデータ解析用ライブラリの一つで、データフレームと呼ばれる表形式のデータを扱うことができます。
また、欠損値の処理、統計処理、データのグループ化、変換、結合のほか、大量のデータを扱うための関数も提供されており、データ分析の効率化を図ることができます。
Numpy
NumPyは、Pythonの数値計算ライブラリの1つで、多次元配列を扱うための機能や線形代数演算、フーリエ変換、ランダム数生成、科学技術計算に必要な機能をそなえています。
またNumPyの多次元配列は高速処理が可能で、大規模な数値計算やデータ分析、機械学習などに広く使われてるとともに、pandasやscikit-learnなどの他のデータサイエンスライブラリでも基礎となっています。
Pythonにおける数値計算やデータ処理に必要不可欠なライブラリです。
Statsmodels
Statsmodelsは、統計モデリングや推定、仮説検定、時系列分析、データの可視化など、統計解析に関する幅広い機能を提供するPythonのライブラリです。
データ分析、統計モデリング、経済学、ファイナンス、マーケティングなど、さまざまな分野で利用されています。
下記に今回の実装で使う、statsmodels からインポートされる関数を紹介します。
seasonal_decompose
seasonal_decompose、時系列分析によく用いられる関数で、時系列データを分解して、トレンド、季節変動、残差の3つの成分に分けることができ、以下の式を用いて実装されます。
ここで、y(t)は時間tにおける観測値、S(t)は季節性、T(t)はトレンド、e(t)はランダムノイズを表します。
トレンド成分は長期的な傾向を表し、季節変動成分は周期的な変化、残差成分はトレンドと季節変動を取り除いた残りの変動を表します。
seasonal_decomposeを使うことで、トレンドや季節変動を取り除き、データの特徴を明確にすることができます。
STL
STL (Seasonal-Trend Decomposition Procedure based on LOESS) は、時系列データの季節変動成分、トレンド成分、残差成分を分解する手法の一つです。
STLは、季節成分とトレンド成分の推定において、さらに柔軟性と頑健性(robust)を持っていますが、計算や処理にかかる時間やリソースが多くなる傾向があります。
一方、seasonal_decompose関数は、比較的簡潔で計算コストが低いですが、データの性質によっては十分な分解ができない場合もあります。
どちらの手法を使用するかは、目的やデータの性質によって異なりますが、データの季節成分とトレンド成分を正確に分解する必要がある場合は、STLを使用してもいいかもしれません。
しかし、シンプルな分解が必要な場合や計算コストを抑えたい場合は、seasonal_decompose関数が適しているかもしれません。
adfuller
ADF(Augmented Dickey-Fuller)テストは、時系列データが単位根過程(非定常過程)であるかどうかを検定するために使用される統計的な検定方法です。
単位根過程とは、時系列データが時間の経過に伴って平均や分散が変化する非定常な性質を持つことを指します。
ADF(Augmented Dickey-Fuller)の数式は以下の通り。
ここで、
- y(t)は時点tにおける時系列データの値。
- y(t-1)は時点t-1における時系列データの値。
- tは時間の指標。
- βtはトレンド成分。
- γは定数項を表。
- Δy(t)は1次階差(一期先との差分)。
- ε(t)は残差項。
ADFテストにおいては、以下の帰無仮説と対立仮説を検定します:
帰無仮説(H0):時系列データに単位根が存在し、非定常である。
対立仮説(H1):時系列データに単位根が存在しない、すなわち定常である。
ADFテストの結果に基づいて、統計量が臨界値よりも小さい場合(一般的に、p値が有意水準よりも小さい場合(通常は0.05))、帰無仮説を棄却し、データが定常であると判断します。
ADFテストは、時系列データの定常性の検証や、単位根の存在に基づいて適切なデータ変換やモデルの選択を行う際に使用されます。
定常な時系列データは、より予測可能であり、一定の統計モデルを適用することができます。
plot_acf, plot_pacf
plot_acf(自己相関グラフ)とplot_pacf(偏自己相関グラフ)は、時系列データの自己相関や偏自己相関を可視化するためのグラフです。
自己相関は、ある時点の時系列データの値と、その時点から一定のラグ(遅れ)だけずれた時点の値との間の相関関係を測ります。
つまり、現在の値が過去の値とどれだけ相関があるかを示します。
一方、偏自己相関は、ある時点の時系列データの値と、その時点から一定のラグだけずれた時点の値との間の直接的な相関関係を測りますが、その間の他のラグの影響を除外した相関を示します。
matplotlib.pyplot
matplotlib.pyplotは、Pythonのデータ可視化ライブラリであるMatplotlibのpyplotモジュールです。
pyplotモジュールは、Matplotlibの中でも特に簡単なグラフやプロットを作成するためのインタフェースを提供します。
以下コードになります。
# # 必要なモジュールの読み込み # import pandas as pd import numpy as np from statsmodels.tsa.seasonal import seasonal_decompose from statsmodels.tsa.seasonal import STL from statsmodels.tsa.stattools import adfuller from statsmodels.graphics.tsaplots import plot_acf, plot_pacf import warnings warnings.simplefilter('ignore') import matplotlib.pyplot as plt plt.style.use('ggplot') #グラフのスタイル plt.rcParams['figure.figsize'] = [12, 9] #グラフサイズ設定
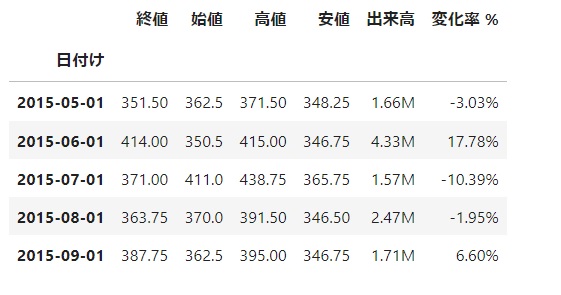
次に、実際のデータを読み込んでみます。
データは米国シカゴコーン先物の過去データから、2018年5月から2023年5月までの月別データになります。
読み込んだデータフレームを分析しやすいように「日付け」コラムをdatetime型に変換し、データフレームのインデックスとして扱います。
df = pd.read_csv('米国シカゴコーン先物 201505-202309.csv')
df["日付け"] = pd.to_datetime(df["日付け"])
df = df.set_index('日付け')
df.head()
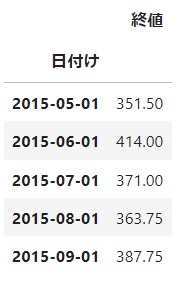
ここからさらに、分析をしやすいようにデータフレームに変更を加えていきます。
具体的には「終値」だけのデータフレームにするため、その他のコラムを drop() 関数を使って削除します。
df_corn_m1509 = df.drop(['安値', '始値', '高値', '出来高', '変化率 %'], axis = 1) df_corn_m1509.head()
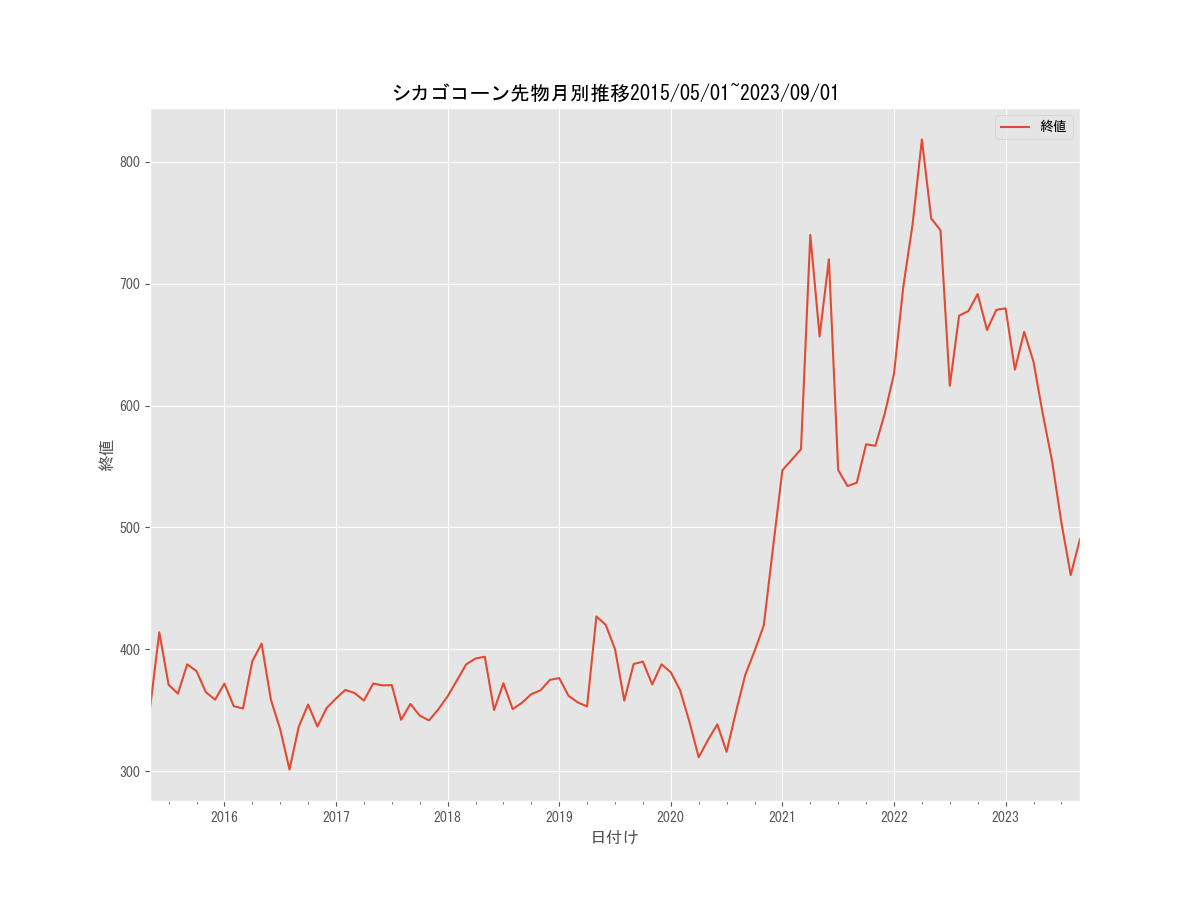
では、このデータフレームをmatplotlibを使って可視化してみましょう。
コードは以下になります。
import matplotlib as mpl mpl.rcParams['font.family'] = 'MS Gothic' #豆腐化防止 df_corn_m1509.plot() plt.title('シカゴコーン先物月別推移2015/05/01~2023/09/01') plt.ylabel('終値') plt.xlabel('日付け') plt.savefig('シカゴコーン先物月別推移2015-5-1-2023-9-1')
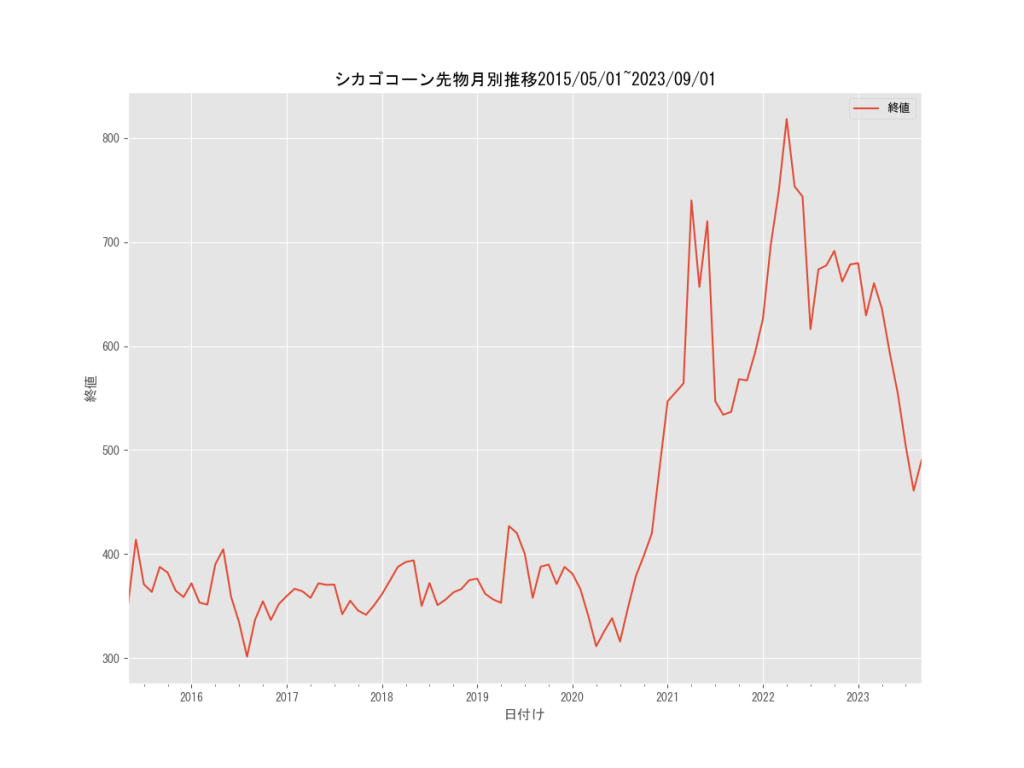
シカゴコーン先物価格を、2018/05/01~2023/09/01までの時系列で可視化してみました。
グラフからわかる特徴として、2020年6月ごろまでは先物価格が300ドルから400ドルの間で取引されていたのが、6月以降急騰。
2022年の3月頃には800ドルの高値を付けています。
時系列データの変動成分の分解
このセクションでは、時系列データを分解して、トレンド、季節変動、残差の3つの成分に分けることができる関数であるStatsmodelsのseasonal_decomposeと、STL LOESS平滑化についても紹介しています。
移動平均法を利用した分解
移動平均法分解は、時系列データから移動平均を計算し、それを基にトレンド成分を推定する手法です。
移動平均は、過去の一定期間のデータを平均化するため、データの変動やノイズを平滑化する効果があります。
つまり、移動平均法分解はデータの滑らかさを活かしたトレンドと季節性の分解手法です。
加法モデルを仮定
移動平均法分解の加法モデルでは、時系列データの値をトレンド成分、季節性成分、残差(またはランダム成分)の和、つまりデータの値をトレンド成分に加え、季節性成分と残差を加えることで元のデータを再現します。
加法モデルでは、トレンドと季節性がデータの変動に対して独立に寄与すると仮定するため、季節性の振幅が時間に依存しないデータを分解する場合に適しています。
以下加法モデルを仮定したコード。
# # 移動平均法を利用した分解(加法モデルを仮定) # result=seasonal_decompose(df_corn_m1509.終値, model='additive', period=12) result.plot() plt.savefig('シカゴコーン先物月別推移2018-5-1-2023-9-1加法')
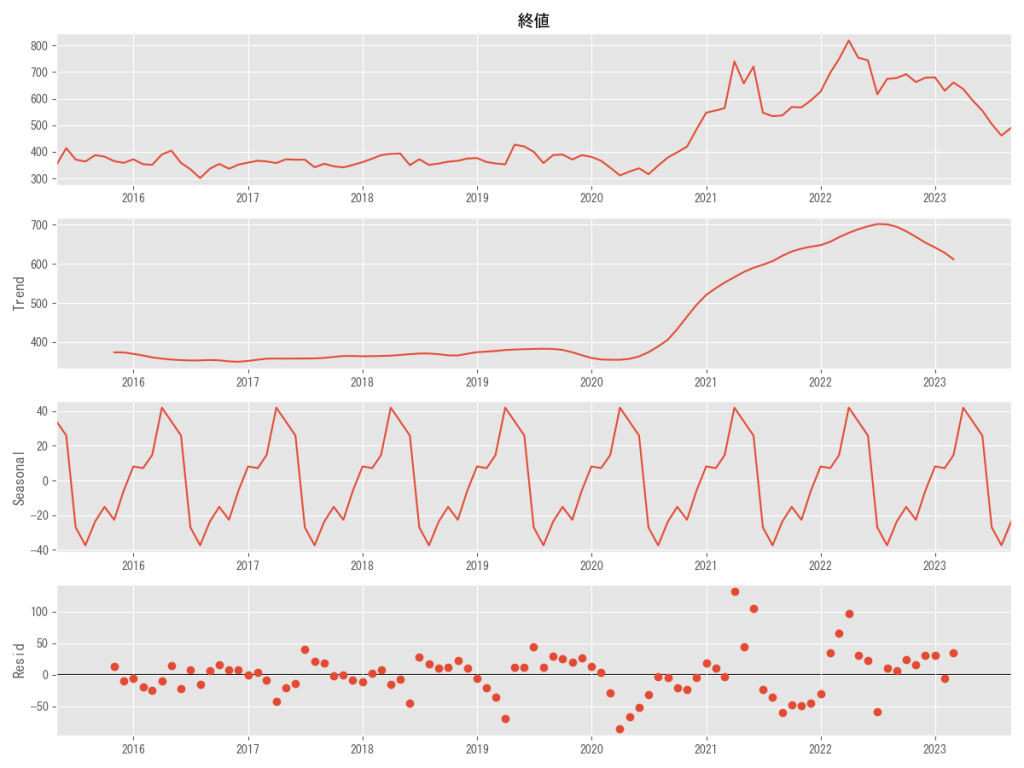
加法モデルにおいて、トレンドは原系列と同じく時間とともに上昇傾向。
季節性(seasonal)には明確に2月から3月頃の価格上昇と7月の価格低下が見て取れます。
残差(resid)においてはパターンのようなものが見えなくもないが、明確に判断することは難しいです。
乗法モデルを仮定
乗法モデルでは、時系列データの値をトレンド成分、季節性成分、残差の積として表現します。
乗法モデルでは、季節性成分はトレンドに対する相対的な変動を表すと解釈されるため、季節性の振幅が時間に依存する場合や、トレンドの変化が指数的であるデータを分解する場合に適しています。
以下乗法モデルを仮定したコードになります。
# # 移動平均法を利用した分解(乗法モデルを仮定) result=seasonal_decompose(df_corn_m1509.終値, model='multiplicative', period=12) result.plot() plt.savefig('シカゴコーン先物月別推移2018-5-1-2023-9-1乗法')
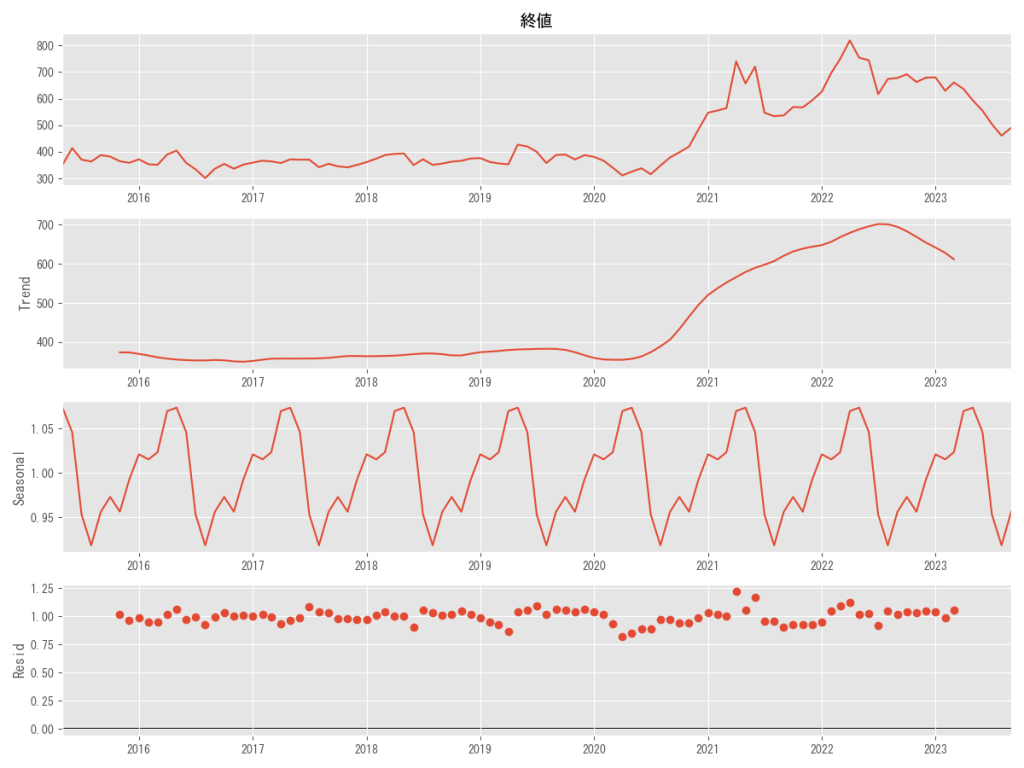
加法モデルと同じように、トレンドは原系列と同じように上昇傾向を表しています。
季節性(seasonal)も一定のパターンが見て取れますが、残差においてはほぼランダムに散らばっているといえるので、加法モデルがデータの変動を上手くとらえているといえます。
STL分解
STLは、LOESS(Locally Weighted Scatterplot Smoothing)平滑化を用いてデータを滑らかな曲線で近似します。
分析プロセスとして、データから局所的なトレンドを推定、そのトレンド成分を除去し、残ったデータから季節成分を推定し、それを除去します。
最後に、残されたデータから残差成分を推定します。
STLは時系列データの分析や予測に広く使用されており、季節性やトレンドを適切にモデリングする際に有用ですが、計算コストが高く大規模なデータセットに対しては時間がかかる場合があります。
LOESS平滑化を利用した分解
LOESS(Locally Weighted Scatterplot Smoothing)平滑化は、非線形回帰手法の一種であり、散布図上のデータ点を滑らかな曲線で近似する手法で、特に時系列データや空間データの解析に広く使用されています。
LOESS平滑化は、近傍のデータ点に対する重み付けにより、曲線の形状が局所的に適応されるため、データに非線形のトレンドやパターンがある場合に有用です。
LOESS平滑化の利点は、滑らかな曲線でデータを近似することで、データのトレンドや変動の特徴を保持しつつノイズを低減することができる一方で、大規模なデータセットに対しては時間がかかることがあります。
また、LOESS平滑化は局所的な特徴に適用されるため、全体的な傾向やパターンを把握する際には注意が必要です。
以下LOESS平滑化を利用した分解用のコードです。
# # STL分解(LOESS平滑化を利用した分解) # # 成分分解 stl=STL(df_corn_m1509.終値, period=12, robust=True).fit() # STL分解結果のグラフ化 stl.plot() plt.savefig('シカゴコーン先物月別推移2018-5-1-2023-9-1SLT')
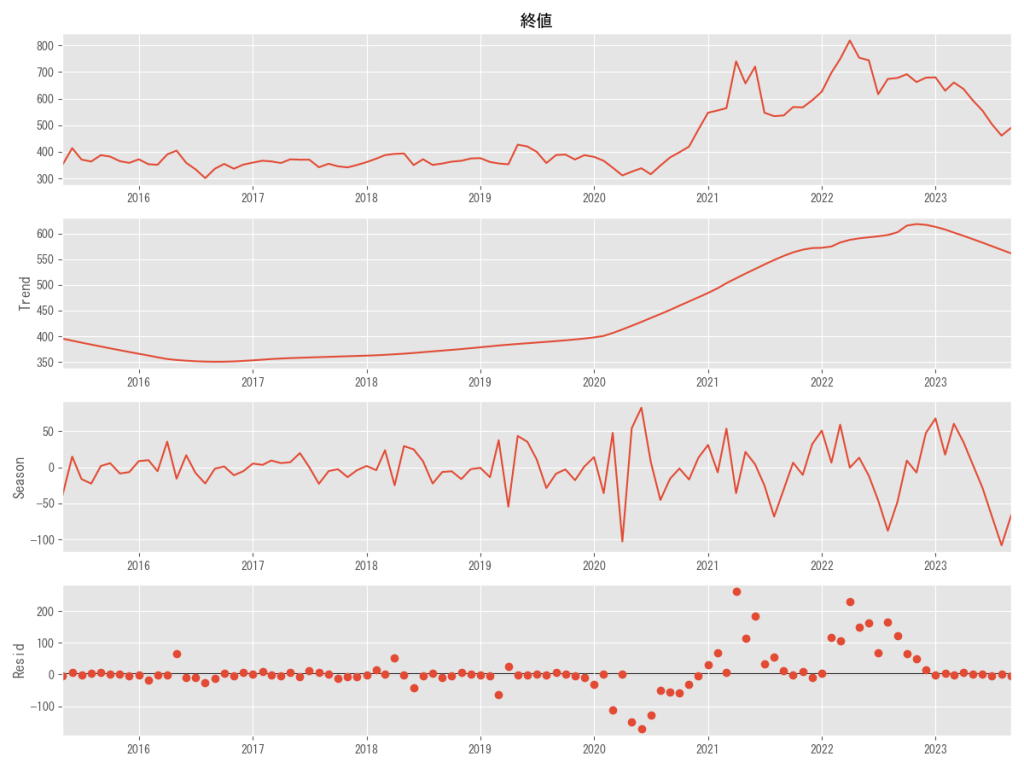
STL モデルにおいて、トレンドは原系列と同じように、上昇傾向にあります。
季節性においては、2018年から2023年にかけて季節性の振幅幅が大きくなっているのが見て取れます。
残差については、価格上昇の二つの山を表してしまっており、LOESS平滑化の欠点である局所的な特徴が強調されたグラフになっています。
まとめ
本記事では、Pythonを使った時系列データの特徴量抽出に必要な処理について解説しました。
時系列データの前処理では、データの性質を理解し、トレンドや季節的な変動、不規則な変動を把握することが重要です。
これらの処理を適用することで、モデルの精度を向上させ、より正確な予測を行うことができます。
プログラミング、機械学習など、無料体験はこちら↓↓↓
![]()

コメント