
「平均値」「中央値」「最頻値」でデータを視覚的、感覚的に確認し、さらにデータがどのような性質を持っているのかを確認するために用いられるのが、分散と標準偏差です。
この記事では、分散と標準偏差とは何か、どのようなときに使われるのか、さらにpythonを使って実際に計算してみます。
この記事で解説するのは以下のポイントになります。
- データ解析の基礎として:標準偏差と分散の重要性
- Pythonを用いた標準偏差と分散の計算方法
- Pythonを用いた標準偏差と分散の実践的な使い方
プログラミング、機械学習など、無料体験はこちら↓↓↓
![]()
データ解析の基礎:分散と標準偏差の重要性
分散とは何か
「分散」とは、簡単に言うとデータセット内の値が平均値からどれだけばらついているかを示す尺度です。
文で説明してもわかりにくいので、とりあえず例を見てみましょう。
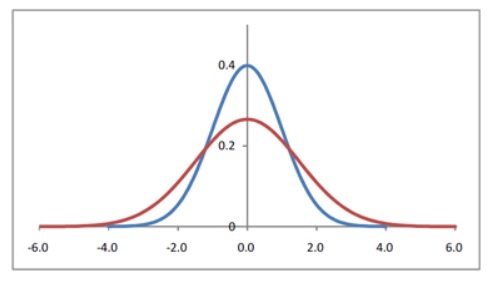
二つのヒストグラムがありますが、青いヒストグラムはすべてのデータがより平均値に近くなっています。
つまり青いヒストグラムの平均値は、このデータ全体をよく表していることになりますね。
反対に赤いヒストグラムは、なだらかな線で左右に広がっていのがわかります。
両端が平均値から離れているため、平均値がこのデータを代表しているとはいいがたいですね。
データが、平均値からどれだけ散らばっているかを示す値が分散というわけです。
母分散
分散には母分散と標本分散の二種類があり、以下のように定義されます。
母集団の分散(Population Variance): 母集団全体に関する分散を表す指標で、通常、母集団の各値と母集団の平均値の差の2乗の平均で計算されます。
数式で表すと、母集団の分散()は以下のようになります:
ここで、 は標本の数、
は各データ点(例:1番目、2番目など)
はデータxのi番目という意味になります。
は母集団の平均値であり、
は合計という意味になります。
標本分散
標本分散とは、標本、つまり母集団から収集されたサンプルから計算される分散を表す指標です。
本来、母集団からデータの散らばりは正確に測定できますが、母集団すべてのデータの収集することは管理された特殊な環境を除いては、ほぼ不可能です。
そのため大抵の場合は母集団からサンプルを収集し、データの散らばりを推測することが一般的です。
以下数式になります。
は標本分散を表し、
は各データ点(例:1番目、2番目など)
はデータxのi番目、
は標本の平均値、
は標本の数になります。
不偏分散
母分散、標本分散とみてきましたが、最後に不偏分散を見てみましょう。
不偏分散は標本分散と同じようにサンプルから得られますが、不偏分散は標本分散よりも正確(不偏)に母分散を推定できます。
以下は不偏分散の公式になります。
不偏分散と標本分散の違いですが、不偏分散は母集団の分散を正確に推定するために用いられ、標本分散は標本(サンプル)内のデータの散らばりを測定するために用いられます。
標準偏差とは何か
標準偏差(Standard Deviation)は、統計学においてデータのばらつきやばらつき具合を表す指標の一つです。
具体的には、データセット内の各データ点が平均値からどれだけ離れているかを示し、標準偏差が小さいほどデータが平均値に集中。
逆に標準偏差が大きいほどデータが平均値から散らばっていることを示します。
標準偏差は以下のような手順で計算されます:
1. 各データ点から平均値を引いて差を求めます。
2. それらの差を二乗します。
3. 二乗した差を合計し、データ数で割った平均値を求めます。
4. その平均値の平方根を取ります。
以下は標準偏差の数式になります。
標準偏差はデータセットがどれくらいばらついているかを表すので、ビジュアルにはヒストグラムや散布図に標準偏差を表す線を描くことがあります。
また、標準偏差は確率論においても重要で、1σ(標準偏差の範囲内)、2σ、3σなどの範囲にデータが分布している確率を示すのにも利用されます。
標準偏差と分散の違い
標準偏差(Standard Deviation)と分散(Variance)は、データのばらつきを測る統計的な指標ですが、いくつかの違いがあります。
計算方法
標準偏差は分散の平方根であり、分散は各データ点と平均との差の二乗の平均です。
単位
- 標準偏差は分散の平方根なので、元のデータと同じ単位を持ち、散らばりの度合いを元の単位で表します。
- 分散の場合、データを二乗した形であるため、標準偏差と比べて単位が大きくなりがちです。
感覚的な解釈
- 標準偏は差散らばりやばらつきの程度を示す指標で、平均値からどれくらい離れているかを示します。標準偏差が小さいほどデータが平均に近く、大きいほど散らばりが大きいことを示します。
- 分散は標準偏差の二乗として定義されているため、直感的な理解が難しいことがあります。一般的には、標準偏差と同様に散らばりの程度を表す指標ですが、具体的な数値は標準偏差に比べて大きくなります。
標準偏差と分散は共に、データのばらつきを表す重要な統計量であり、どちらを使うかは具体的な文脈や解析の目的に依存します。
標準偏差が一般的により直感的な解釈を提供するため、一般的に使用されることが多いです。
Pythonでの標準偏差と分散の計算方法
では実際に分散と標準偏差を計算してみましょう。
使用するデータは「Python を使った度数分布表とヒストグラムの作成」で用いた、「例題で学ぶ統計入門」の救急車の出動回数を使ってみました。
基本的にデータは何でもいいので、お近くの手に入りやすいデータを使ってください。
また、関数を使えば一行で分散と標準偏差を出すことができるのですが、その前に実際に数式をプログラムに当てはめて計算してみます。
Pythonを使った分散の計算
Python には、分散と標準偏差を計算できるコードがすでにあるのですが、数式をコードに落とし込む練習ということで、実際にコードを書いてみます。
分散のコード
以下分散のコードになります。
def var(x): mu = np.mean(x) sigma = 0.0 n = len(x) for i in range(n): sigma += (x[i] - mu)**2 sigma /= n return sigma
data_var = var(data) data_var 1.666009204470743
以上分散は1.666…. と計算されました。
ちなみにnumpy を使うと以下のコードになり、分散が1.666…と計算されました。
np.var(data, ddof=0)
1.666009204470743
標準偏差のコード
同じように標準偏差も計算してみましょう。
標準偏差のコードは以下になります。
def std(x): mu = np.mean(x) sigma = 0.0 n = len(x) for i in range(n): sigma += (x[i] - mu)**2 sigma /= n return np.sqrt(sigma)
data_std = std(data) data_std 1.2907397896054584
標準偏差は1.290…となります。
標準偏差も分散と同じようにnumpyを使うことができるので、コードを使って
np.std(data, ddof=0)
1.290739789605458
標準偏差を1.290…となります。
プログラミング、機械学習など、無料体験はこちら↓↓↓
関連記事↓↓↓

![]()

コメント